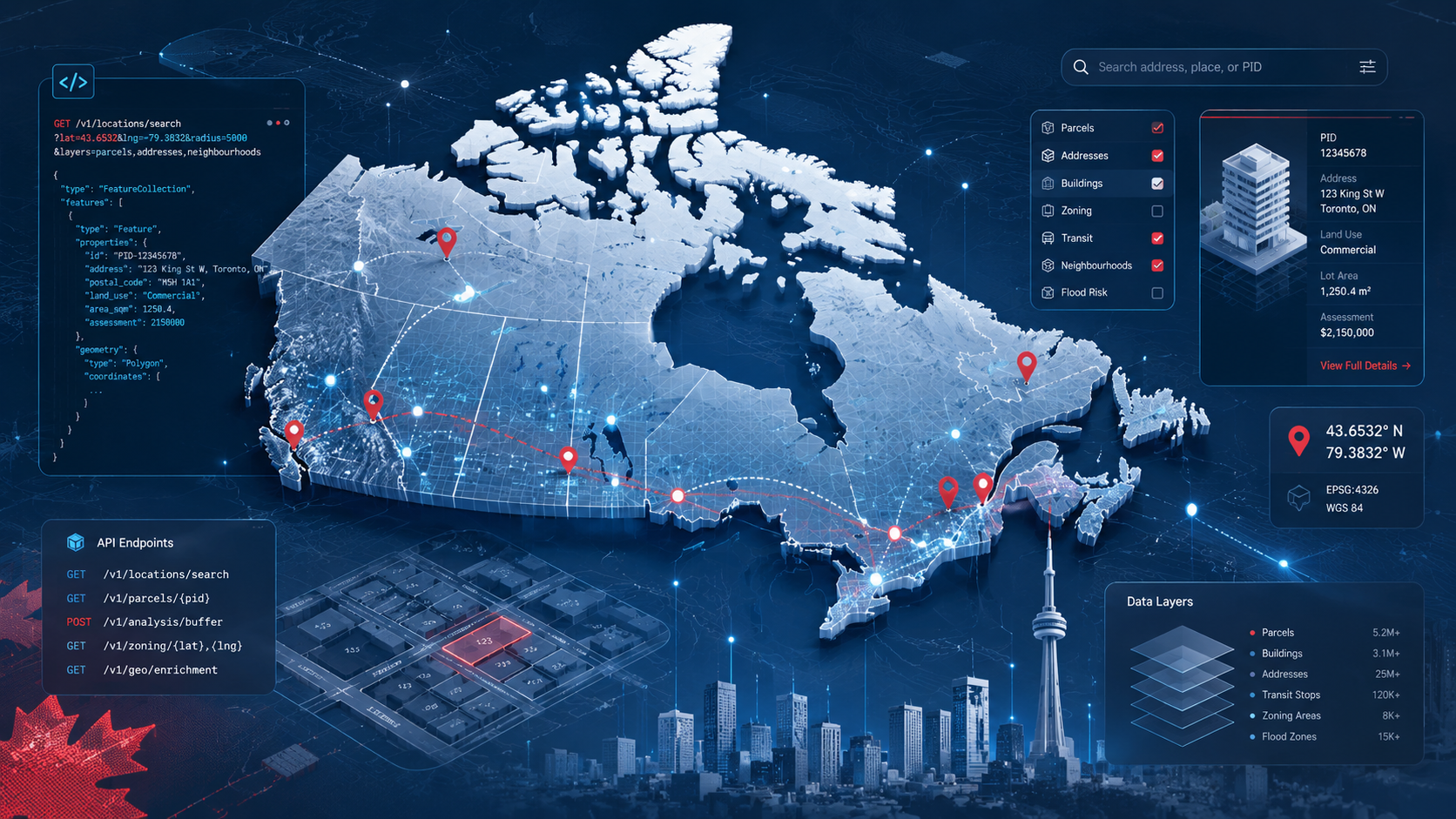
The first thing most PropTech developers discover when they start building a Canadian real estate product is that the data situation is considerably messier than they expected. There is no single authoritative source. There is no Plaid for Canadian property data. What exists is a patchwork of provincial land registries, municipal open data portals, Statistics Canada releases, and private data aggregators — each with different schemas, update frequencies, coverage gaps, and licensing terms.
This guide is for developers who are past the "what do I need?" phase and are now asking "where do I get it, and how do I build something that actually works?"
Start With the Data Model, Not the APIs
Before you evaluate any specific API, get clear on what your product actually needs. Location data requirements in real estate split into a few distinct categories, and the right source is different for each:
Address resolution
Converting a raw string like "142 maple ave toronto" into a canonical, geocoded, validated Canadian address. This is the foundation — everything else depends on it.
Geographic context
What neighbourhood is this address in? What census dissemination area? What municipality, school zone, or community boundary? Polygon-in-point lookup at query time.
Property intelligence
Building characteristics, permit history, assessment data, ownership history. Property-specific records that describe the physical structure and its history.
Place context
Points of interest, walkability, transit access, amenities within distance thresholds. Answers the question "what is near this address?"
Area statistics
Demographics, income, age distribution, household composition — from Census and other sources, aggregated to neighbourhood or DA level.
Environmental context
Natural geography — lakes, Crown land, wildlife units, trails, campgrounds. Especially relevant for rural, cottage, and waterfront properties.
Most products need layers 1–4 at minimum. Layers 5 and 6 become important as you move into richer property pages, rural markets, or insurance and risk products.
The Canadian Data Landscape Is Genuinely Fragmented
Here's the reality of how Canadian location data is structured: there is no national property data registry. Property assessment, permit, and ownership data is controlled provincially — and in practice, municipally. A permit record in the City of Toronto has a completely different structure from one in the Regional Municipality of Peel, which has a different structure from one in Halifax Regional Municipality.
Census data is national (Statistics Canada), but it's released on a 5-year cycle with a 2-year lag, in a schema that requires significant processing to be useful in a real-time API. Boundaries shift between censuses. Dissemination areas are renumbered. Joining census data to a live address stream is a non-trivial ongoing maintenance problem.
Points of interest data in Canada comes from OpenStreetMap contributions (variable quality, especially outside major urban centres), Google Places (expensive at scale, licensing restrictions for display), HERE (enterprise pricing), and a small number of Canadian-specific aggregators. None of them are complete.
Address data itself is governed by Canada Post's SERP licensing, which restricts redistribution and places specific obligations on how address data can be cached, combined with other datasets, and displayed.
What to Evaluate in a Location Data API
When you're assessing whether an API is the right fit for your product, these are the questions that matter most — beyond the obvious ones about pricing and uptime:
1. What is the update frequency for each layer?
An address geocoding layer needs to be updated when new subdivisions are built. Permit data needs to be updated as municipalities release new records. Demographic data is inherently stale by the time it reaches you — but there's a meaningful difference between data that's 18 months old and data that's 7 years old. Ask specifically, not generally.
2. How is coverage defined?
A Canadian API that says "national coverage" could mean anything from "we have data for every six-digit postal code" to "we have address-level records for every Canada Post delivery point." It could also mean "we have good urban coverage and thin rural coverage." Push for a specific answer: what percentage of Canadian addresses return non-null results for each data layer?
3. How are ambiguous queries handled?
Canadian addresses have endemic ambiguity problems. Multi-unit buildings, rural routes, addresses that exist in multiple provinces, French and English name variants for the same street — all of these create edge cases that a naive geocoder handles badly. Ask for the failure mode documentation, not just the happy path.
4. What are the licensing terms for derived data?
This is the question that bites developers later. If you build a feature that displays neighbourhood demographics from a third-party API, and that API's data comes from Statistics Canada, you need to understand both the API provider's terms and the underlying dataset's terms. Some providers allow caching. Some don't. Some require attribution. Some prohibit use in insurance products. Read the licensing carefully before you build on it.
Building With a Multi-Layer API vs. Assembling Your Own Stack
The build-vs-buy question in location data has a different answer than it did five years ago. In 2020, the case for assembling your own stack was reasonable — no single Canadian provider had the coverage or depth you needed, so you'd pull addresses from one source, neighbourhood boundaries from another, and POI data from yet another.
That calculus has shifted. The maintenance cost of a homegrown location data stack is non-trivial: you're responsible for monitoring data source changes, re-running normalization pipelines when upstream schemas shift, and handling the licensing complexity of multiple providers simultaneously. For most product teams, that's not where you want to spend engineering time.
The better question now is: which single provider can cover the most of what you need with acceptable quality and coverage, and what do you bolt on top for the gaps?
The Neighbourly API Design Philosophy
Neighbourly is designed around a simple principle: pass a Canadian address or coordinate, get back everything useful about that location in a single structured response. The Real Estate Data API aggregates address intelligence, neighbourhood context, demographics, building permits, energy data, and POI data into a single call.
For developers building property detail pages, this means one API integration replaces six separate data sources. For teams building map-based search products, the coordinate-based endpoints return the same data keyed to a lat/lng rather than an address string.
The Environmental Data API handles the rural and waterfront use case — lake boundaries, Crown land, wildlife management units, trails, and campgrounds — with the same coordinate-queryable interface.
Both APIs are designed for real-time query and bulk enrichment. If you're pre-populating a database with enriched listing records, you can batch-query at ingestion time. If you're enriching at page load, the response time is designed to fit within a reasonable UX budget.
A Note on Canadian vs. U.S. Developer Resources
One practical difficulty for Canadian PropTech developers is that most of the developer education content online is US-centric. Tutorials about building real estate apps assume Zillow's API, ATTOM, or CoreLogic. Stack Overflow answers assume US census geographies. Even the open source tooling (like Mapbox's Canadian data layers) has historically had thinner coverage north of the border.
This is changing, slowly. The PropTech ecosystem in Canada is growing — particularly in Toronto, Vancouver, and Montreal — and with it, the developer tooling. But it means you should be skeptical of tutorials that claim to apply to Canadian data without specifically addressing the differences. The edge cases are different. The licensing landscape is different. The fragmentation is different.
If you're building for the Canadian market, talk to vendors who are explicitly built for it, not ones that have added Canada as an afterthought to a US-first product.